In diesem Beitrag zeigen wir Ihnen, welche Schritte bei der Einführung einer Anomalieerkennung in Automationsnetzen zu beachten sind. Behandelt werden grundsätzliche Anforderungen an Lösungen zur Netzwerkanomalieerkennung, welche zwei Phasen es bei der Integration gibt und Entscheidungshilfen, wo diese am besten platziert werden.
Schritt 1: Anforderungen an Netzwerkanomalieerkennung definieren
Zunächst sollten Sie sich Gedanken dazu machen, welche Fähigkeiten die Lösung besitzen soll. Soll diese nur rein passiv den Verkehr analysieren oder auch aktiv den Systemstatus der Teilnehmer abfragen? Sollen die Daten in weitere Systeme fließen, um diese im Rahmen von Industrie 4.0-Aspekten auszuwerten? Betreiben Sie bereits ein ISMS, das die Lösung durch Schwachstellen- und Risikomanagement unterstützen kann?
Die folgenden Anforderungen helfen Ihnen dabei, sich Gedanken über den Einsatz einer Monitoring-Lösung zu machen:
Passive oder aktive Erkennung
Je nach Kritikalität der Teilnehmer im Netz kann eine aktive Erkennung zu riskant sein, um nicht den Prozess zu stören. Lösungen, die aktive Erkennung einsetzen, sollten in jedem Fall die vorliegenden Systeme und Protokolle korrekt unterstützen. Eine passive Erkennung kann unter Umständen jedoch nicht den vollen Netzwerkverkehr mitlesen, da dies von der Platzierung abhängt. Hierzu später mehr im Kapitel zur Einführung einer Lösung.
Exportfähigkeiten in andere Formate
Die Lösung sollte den Export der erfassten Daten in weitere Formate unterstützen. Dies ist insbesondere hilfreich, um die Informationen in weiteren Programmen wie z.B. Microsoft Excel weiter zu verwenden. Auch für forensische Zwecke ist ein Export hilfreich. So können im Falle eines außergewöhnlichen Ereignisses die Daten gespeichert und näher untersucht werden. Hervorzuheben ist hier das PCAP-Format, welches weiterführende Analysen mit Wireshark ermöglicht. Weitere sinnvolle Exportformate sind CSV oder XLSX.
Anbindung an zentrales Log-Management
Rollenbasiertes Berechtigungskonzept
Um die Vertraulichkeit und Integrität der Daten zu gewährleisten, sollte die Möglichkeit bestehen, die Nutzer der Lösung mit einem entsprechenden Berechtigungskonzept auszustatten. So sollte beispielsweise ein User, der lediglich Leseberechtigung benötigt, nicht in der Lage sein gesammelte Daten zu verändern (Principle of least privilege).
Konfigurierbare Filterregeln
Die Lösung sollte Ihnen die Möglichkeit bieten, die eingelesenen Datensätze durch individuell anpassbare Filter zu sortieren und fokussiert zu analysieren. Außerdem sollten sich Alarme dadurch ebenfalls klassifizieren lassen, um diesen unterschiedliche Priorisierungen zu geben.
Integriertes Risikomanagement
Wurden Anomalien entdeckt oder Schwachstellen gefunden, können diese Daten in einem integrierten Risikomanagement verarbeitet werden. Dies orientiert sich am PDCA-Zyklus verschiedener Normen wie zum Beispiel der ISO 27000 oder IEC 62443.
Deep-Packet-Inspection
Soll über die klassische IP-Kommunikation hinaus noch tiefer in die Pakete eingesehen werden, um z.B. falsche Funktionscodes oder ungewöhnliche Datenwerte zu erkennen, benötigt die Lösung Deep-Packet-Inspection-Fähigkeiten. Dies ist insbesondere vom Aufbau Ihres Automatisierungsnetzes und den Zielen einer Anomalieerkennung abhängig. Mehr dazu finden Sie in unserem Einführungsbeitrag zu Netzwerkanomalieerkennung.
Nachdem Sie sich Gedanken über die Anforderungen an die Lösung gemacht haben, können Sie Anbieter dahingehend prüfen oder darauf ansprechen.
Schritt 2: Platzierung der Monitoring-Lösung im Automationsnetz bestimmen
Besonders interessante Stellen zur Integration einer Monitoring-Lösung sind externe Schnittstellen wie zum Beispiel Verbindungen zu externen Standorten, Fernwartungszugänge oder Systeme, an denen externer Dateiaustausch stattfindet. Wichtig bei der Integration ist, dass bei Anschluss der Lösung an einem Switch auch nur der Verkehr analysiert werden kann, der tatsächlich über diesen Switch verläuft. In der folgenden Grafik ist eine Integration innerhalb des Anlagenrings an einem Switch dargestellt.
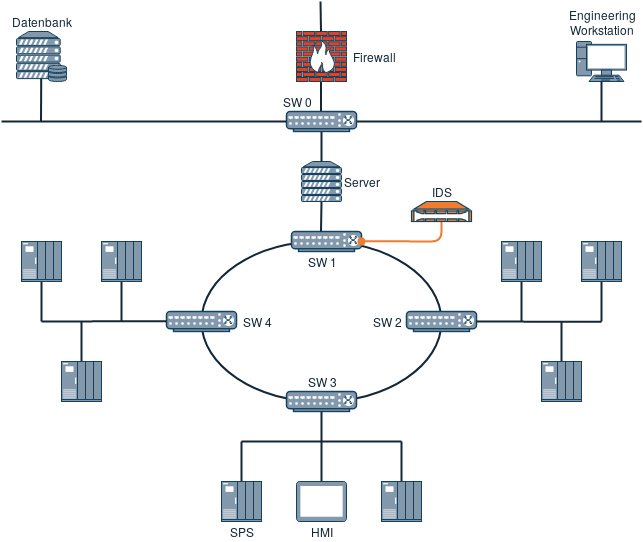
In dieser Konstellation würde jegliche Kommunikation, die über den Switch SW 1 verläuft, mitgelesen werden. Darunter fällt zum Beispiel sämtliche Kommunikation vom Server zu den entsprechenden Teilnehmern. Nicht erkannt werden allerdings potenzielle Verbindungen zwischen den Teilnehmern an SW 3 und SW 4, da diese nicht über SW 1 verlaufen.
Die nächste Grafik veranschaulicht die Integration innerhalb des Produktionsnetzes oberhalb der Anlage.
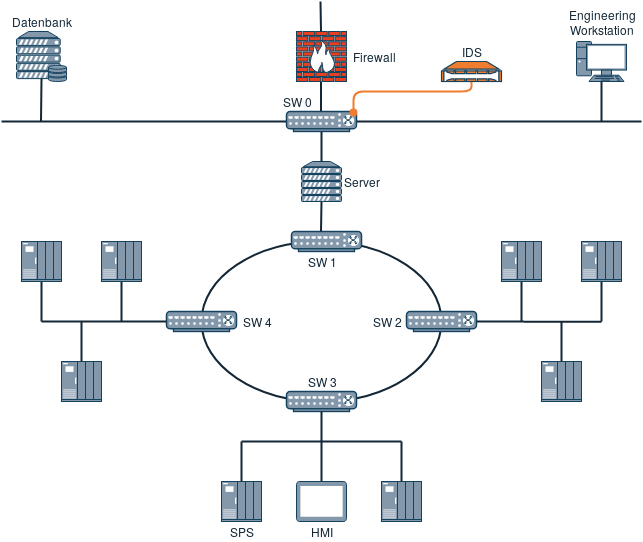
Hierbei können z.B. Verbindungen zwischen Server und Datenbank, sowie Verbindungen und Verbindungsversuche ins Internet mitgelesen werden.
Schritt 3: Bestehende Netzwerkkomponenten für den Einsatz prüfen
Zunächst sollten Sie prüfen, welche Systeme und welche Art der Kommunikation überwacht werden sollen. Viele Lösungen zur Anomalieerkennung werden als separates Gerät an einen oder mehrere Switche angeschlossen, um passives Monitoring zu betreiben. Die Switche müssen hierzu das sogenannte Port-Mirroring, also die Weiterleitung sämtlicher Daten an einen definierten Port, unterstützen. Dabei ist Vorsicht angebracht: Nicht alle Switche besitzen diese Fähigkeit oder besitzen sie nur für jeweils einen einzigen Port und nicht für mehrere Ports gleichzeitig! Achten Sie darauf, ob es sich bei dem eingesetztem Gerät um einen „Managed Switch“ handelt. Prüfen Sie also im Voraus, ob die bestehenden Geräte bereits Port-Mirroring unterstützen, oder überlegen Sie, welche Switche gegebenenfalls getauscht werden müssen.
Alternativ besteht auch die Möglichkeit, die Sensoren als sogenannte „Wire Taps“ direkt in die Kabelverbindungen einzubringen. Hierzu müssen die relevanten Kabelverbindungen an den gewünschten Stellen aufgetrennt und der Sensorknoten zwischengeschaltet werden. Das erspart die Nutzung von Managed Switches mit Port Mirroring Kapazitäten, allerdings können dadurch tendenziell weniger Daten ausgelesen werden als durch eine Platzierung am Switch.
Schritt 4: Status Quo der Netzwerkkommunikation erfassen
Bei der Integration einer Lösung zur Netzwerkanomalieerkennung sind grundsätzlich zwei Phasen zu unterscheiden. In der Anlernphase werden zunächst die Teilnehmer und Kommunikationsverbindungen erfasst. Das Ziel dieser Phase ist es, einen sauberen Stand zu erfassen, von dem ausgehend Anomalien erkannt werden können.
Hier stellt sich bereits eine spannende Frage: Wie können Sie sicherstellen, dass sich nicht bereits ein Angreifer oder eine Schadsoftware in Ihrem Netzwerk befindet? Aus diesem Grund sollten Sie die anfänglich aufkommenden Daten gründlich auf Konsistenz und Sinnhaftigkeit prüfen. Dabei ist manueller Einsatz erforderlich, am besten durch das Personal, welches das Netzwerk betreut und später auch für die Verwaltung der Lösung verantwortlich ist. Hierbei gilt es auf Kommunikation über unerwünschte Protokolle oder zwischen Systemen, die standardmäßig nicht (viel) miteinander sprechen sollten, zu achten.
Ist diese Phase abgeschlossen, kann der aktuelle Stand als bekannter „Snapshot“ festgehalten und akzeptiert werden. Unter Umständen lohnt es sich bereits zu diesem Zeitpunkt, einen entsprechenden Export der Daten anzufertigen.
Schritt 5: Permanente Überwachung starten und in Incident-Response Prozess integrieren
Danach beginnt die Phase der permanenten Überwachung auf Anomalien. Dies beinhaltet auch die Auswertung von generierten Alarmen durch geschultes Personal. Wie Anomalien in einem Automationsnetz aussehen können, haben wir bereits in unserem vergangenen Einführungsartikel besprochen. Wichtig ist insbesondere, dass auftretende Alarme auch tatsächlich bearbeitet werden und dies in einen entsprechenden Incident-Response-Prozess integriert wird.
Außerdem sollte darauf geachtet werden, dass die Zahl der „False Posives“, also der fälschlicherweise generierten Alarme, die in Realität einen ungefährlichen Ursprung haben, möglichst gering ist. Hierzu sollten Filterregeln oder die Analyse-Engine der Lösung so konfiguriert werden, dass diese gleich als unbedenklich eingestuft werden. Ansonsten droht Frustpotenzial beim verantwortlichen Personal und dadurch eine Verringerung der Effektivität des Einsatzes.
Fazit
Anomalieerkennung und Monitoring in Automationsnetzen kann als zusätzliche Schutzschicht umgesetzt werden, um Störungen und Angriffe zu entdecken. Durch diese Voraussetzungen können weitere Maßnahmen zielgerichtet abgeleitet und implementiert werden. Hiernach wird eine weitere Ebene des Defense-In-Depth-Prinzips umgesetzt und somit das Sicherheitsniveau nochmals gesteigert.
Neben der reinen Datenanalyse können Monitoring-Lösungen noch weitere positive Effekte haben. Durch die Erfassung der Teilnehmer und automatisierten Erstellung entsprechender Listen kann ein automatisiertes Asset-Inventar erzeugt werden. Dies ist als sehr positiv für die allgemeine Sichtbarkeit im Netz zu bewerten und kann Ihnen dabei helfen, alte Systeme zu identifizieren, Softwarestände festzuhalten und darauf aufbauend weitere Änderungen zu planen.
Darüber hinaus werden durch den Einsatz einer Netzwerk-Monitoringlösung in der Regel mehrere Anfoderungen bei der Umsetzung von Normen (beispielsweise der IEC 62443) oder bei der Einführung eines ISMS erfüllt.
Ob und an welchen Stellen Sie Netzwerkanomalieerkennung nutzen können, hängt von Ihren individuellen Gesamtsituation ab. Relevante Faktoren sind die Kritikalität Ihrer Systeme und welche Daten Sie überwachen wollen. Das beeinflusst auch die Entscheidung, ob ein rein passives oder ein aktives System notwendig ist und ob Deep-Packet-Inspection-Fähigkeiten benötigt werden.
Checkliste: Angriffserkennung in KRITIS Betrieben

CEO & Founder

Die Anforderung nach „Angriffserkennung für kritische Infrastrukturen“ sorgt für zusätzlichen Stress bei der Vielzahl an notwendigen Schutzmaßnahmen.
Deshalb haben wir eine Checkliste: Angriffserkennung in KRITIS Betrieben erstellt, die Ihnen einen effizienten Überblick gibt und vor allem eine strukturierte Bearbeitung ermöglicht.

